Selected Publications
Action Recognition
2025
-
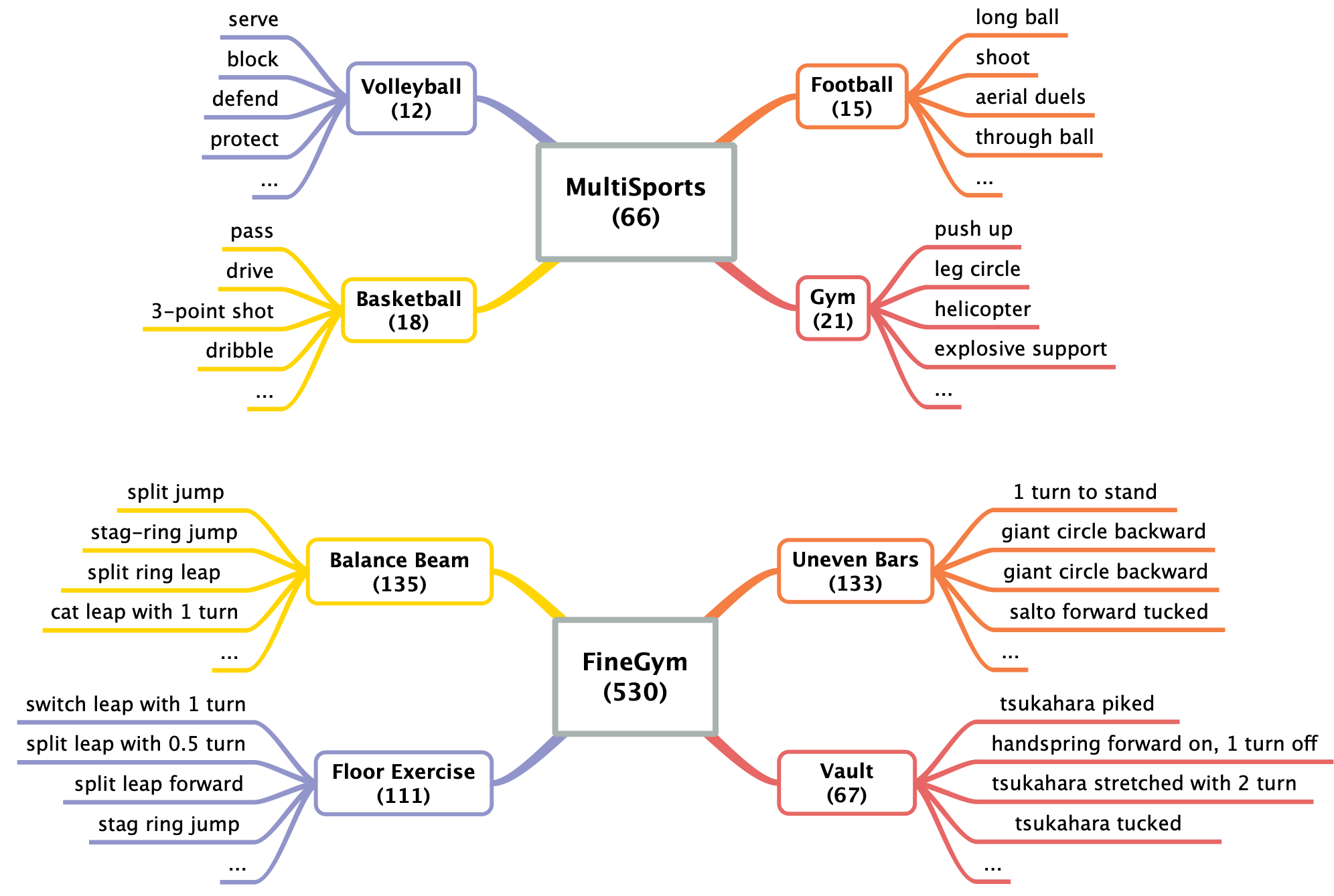
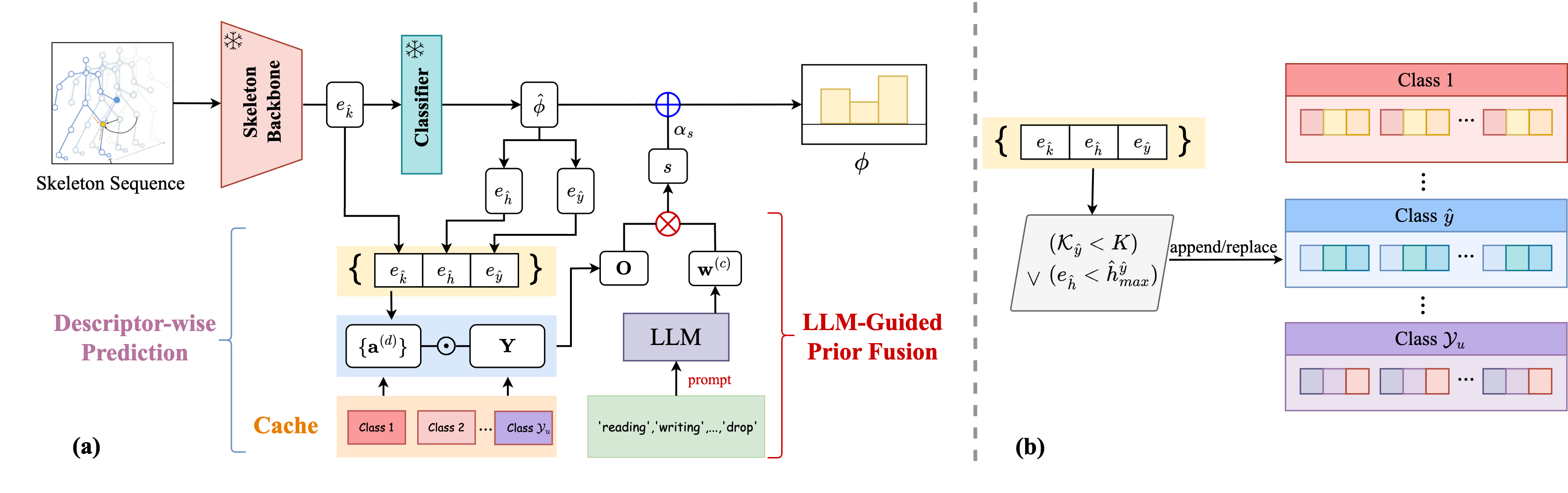
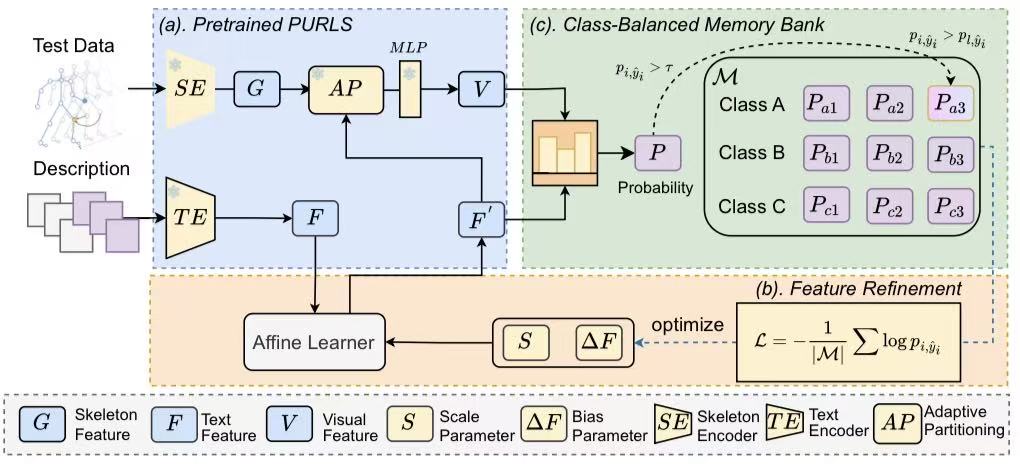 DynaPURLS: Dynamic Refinement of Part-aware Representations for Skeleton-based Zero-Shot Action RecognitionArxiv 2025| arXiv preprint
DynaPURLS: Dynamic Refinement of Part-aware Representations for Skeleton-based Zero-Shot Action RecognitionArxiv 2025| arXiv preprint -
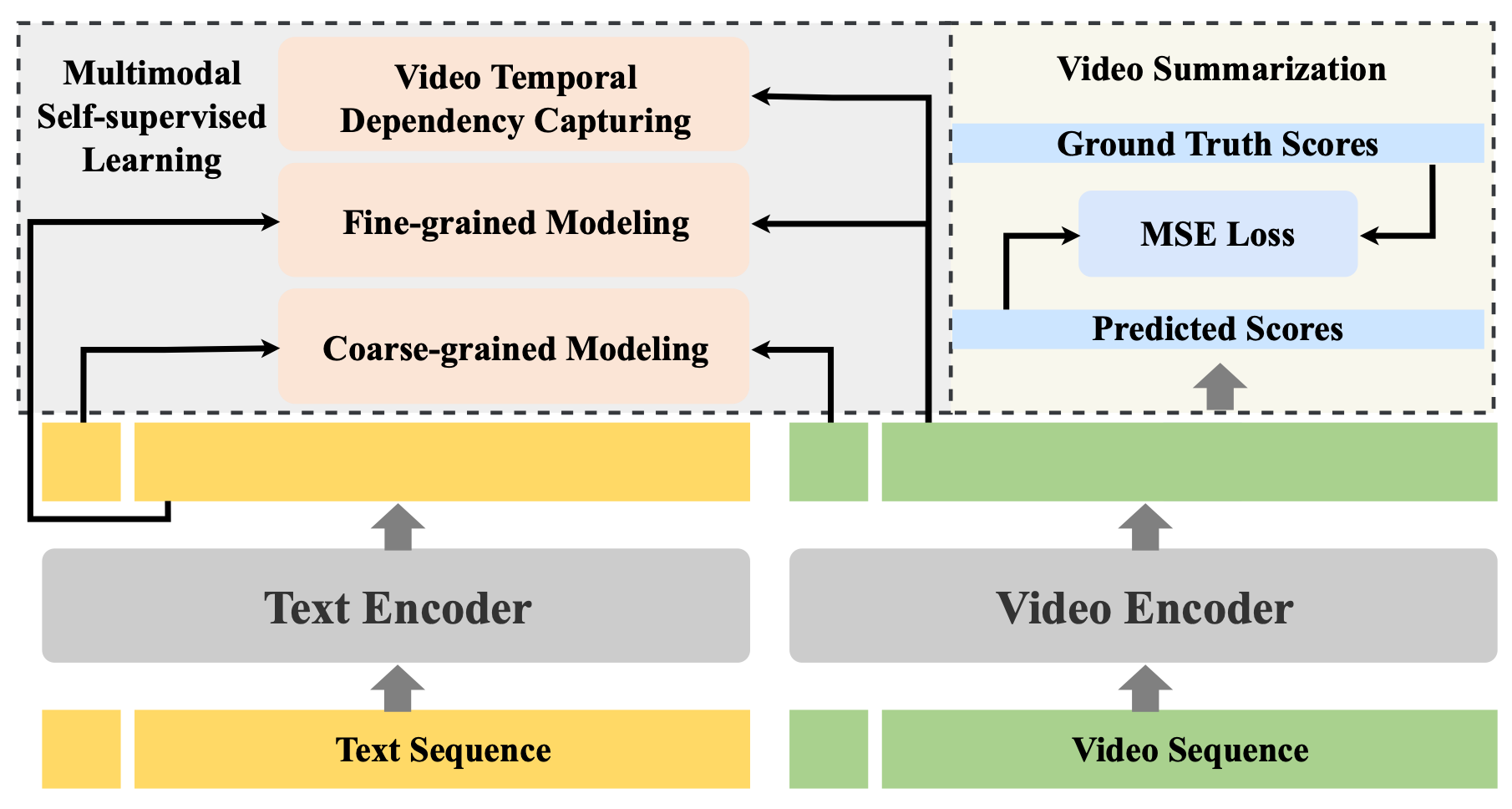
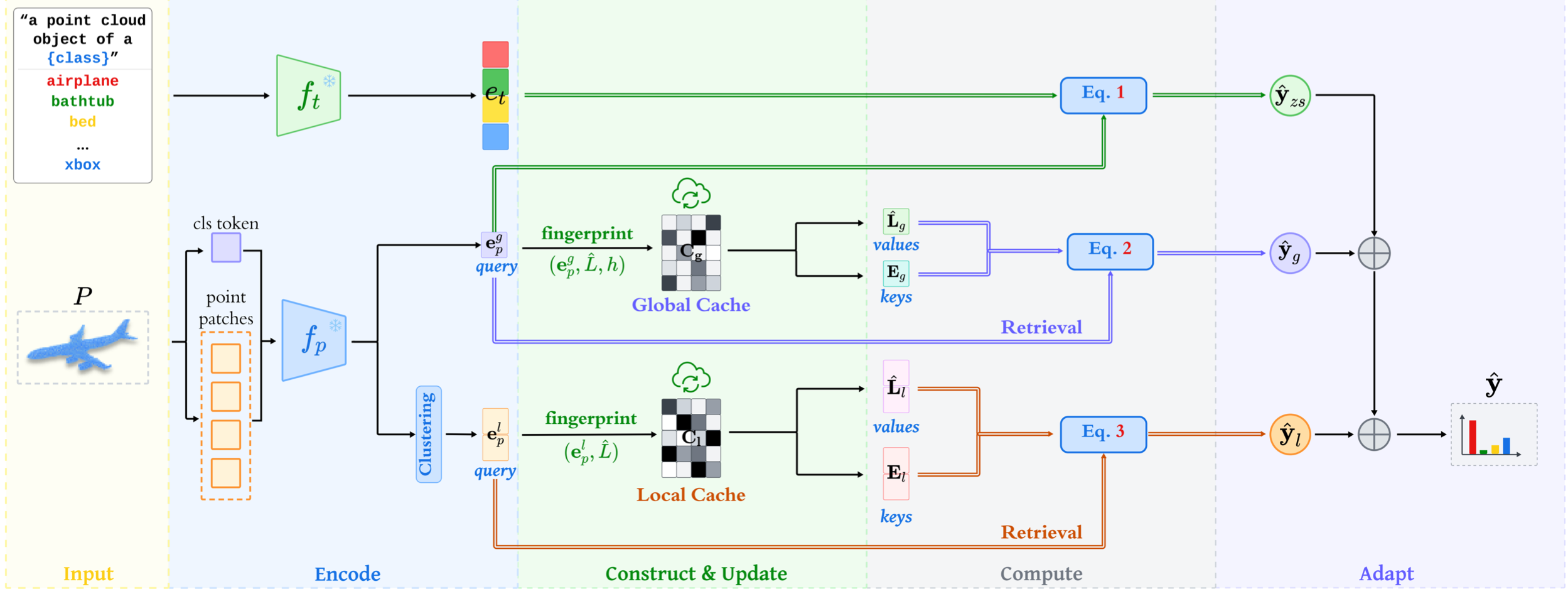
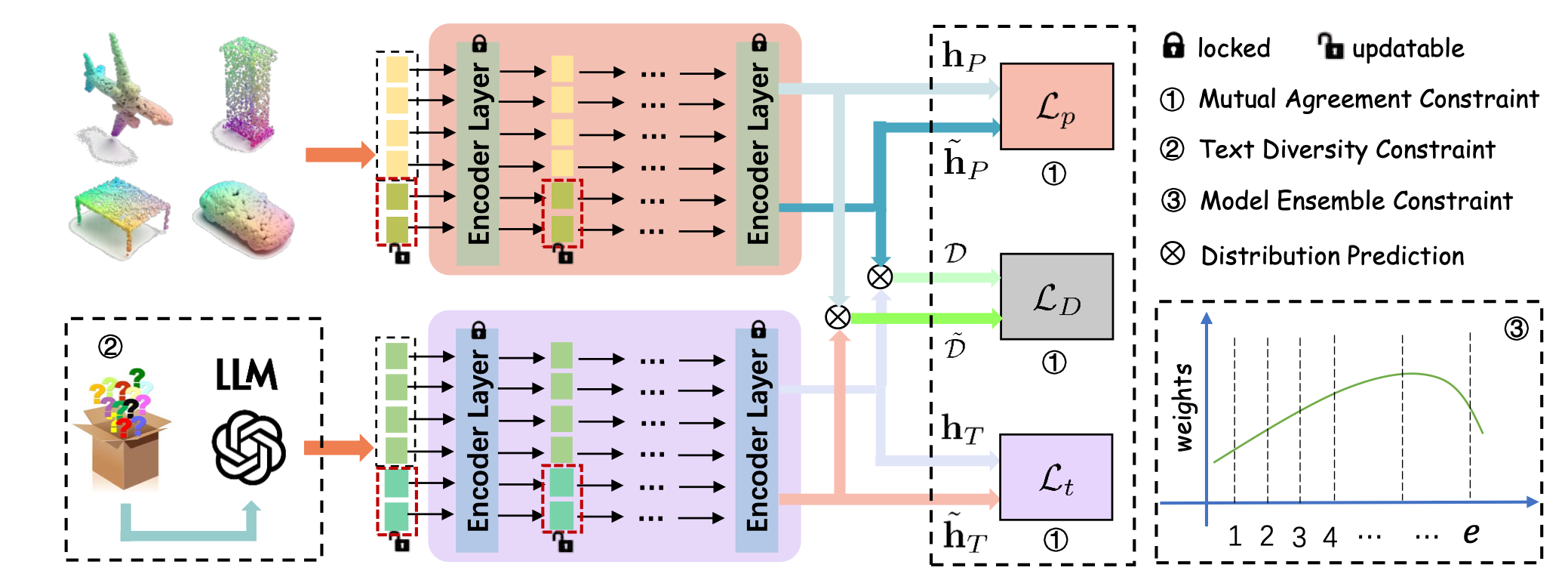
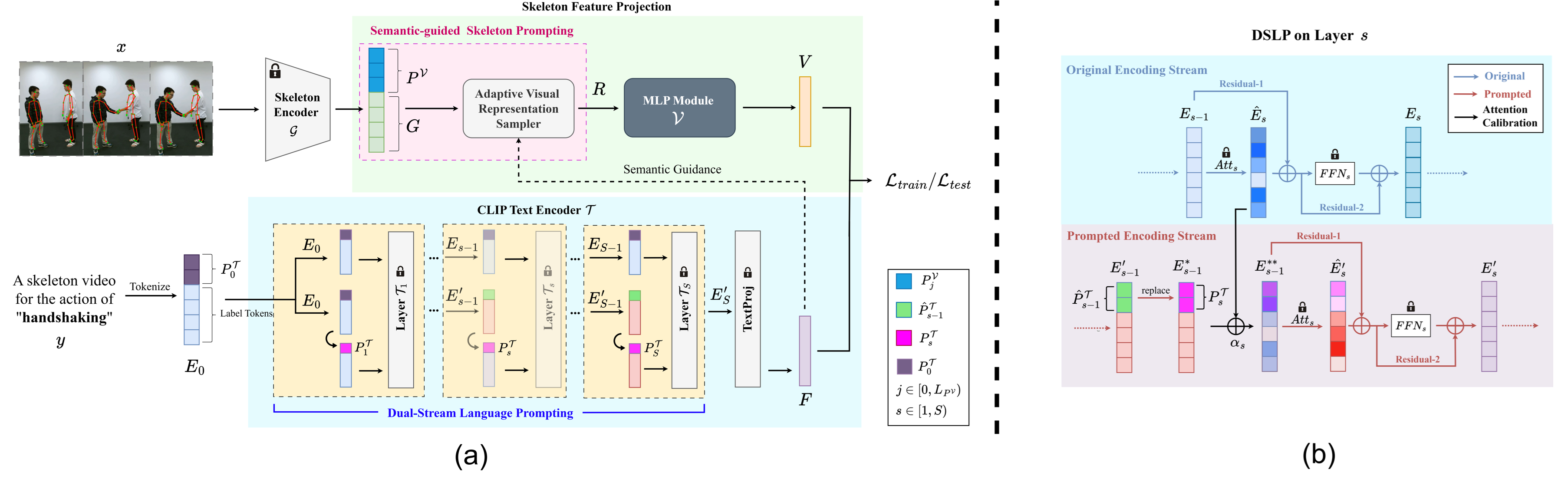 Semantic-guided Cross-Modal Prompt Learning for Skeleton-based Zero-shot Action RecognitionCVPR 2025| Proceedings of the Computer Vision and Pattern Recognition ConferenceCCF-ACORE-A*
Semantic-guided Cross-Modal Prompt Learning for Skeleton-based Zero-shot Action RecognitionCVPR 2025| Proceedings of the Computer Vision and Pattern Recognition ConferenceCCF-ACORE-A*
2024
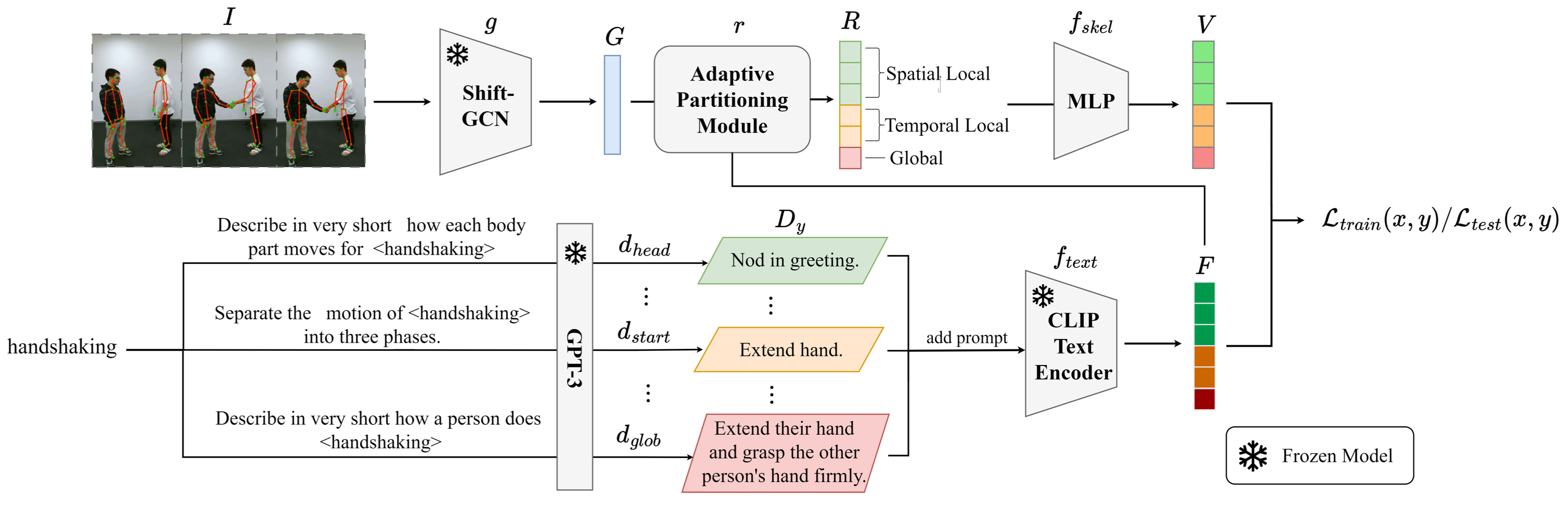
2022
-
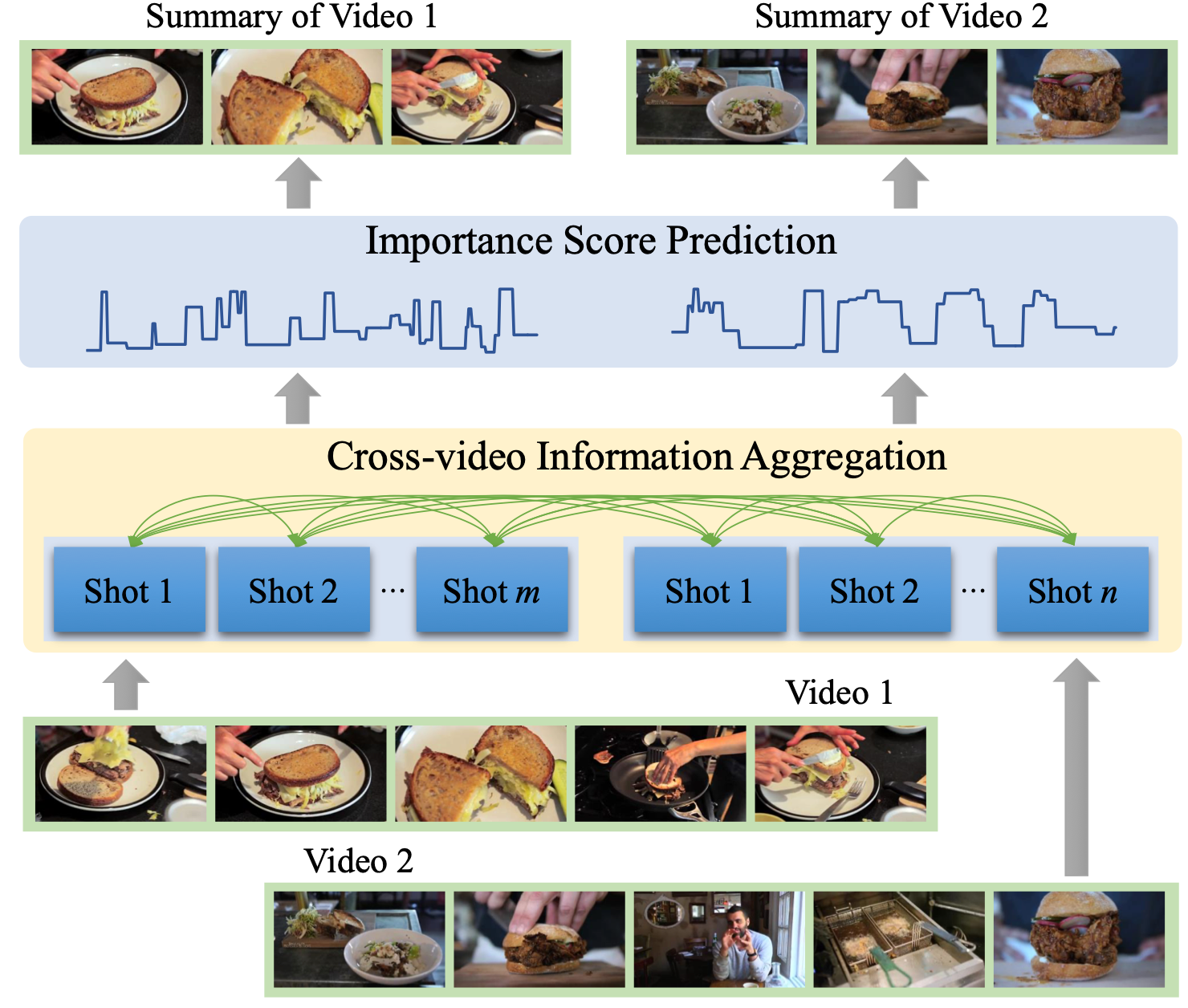
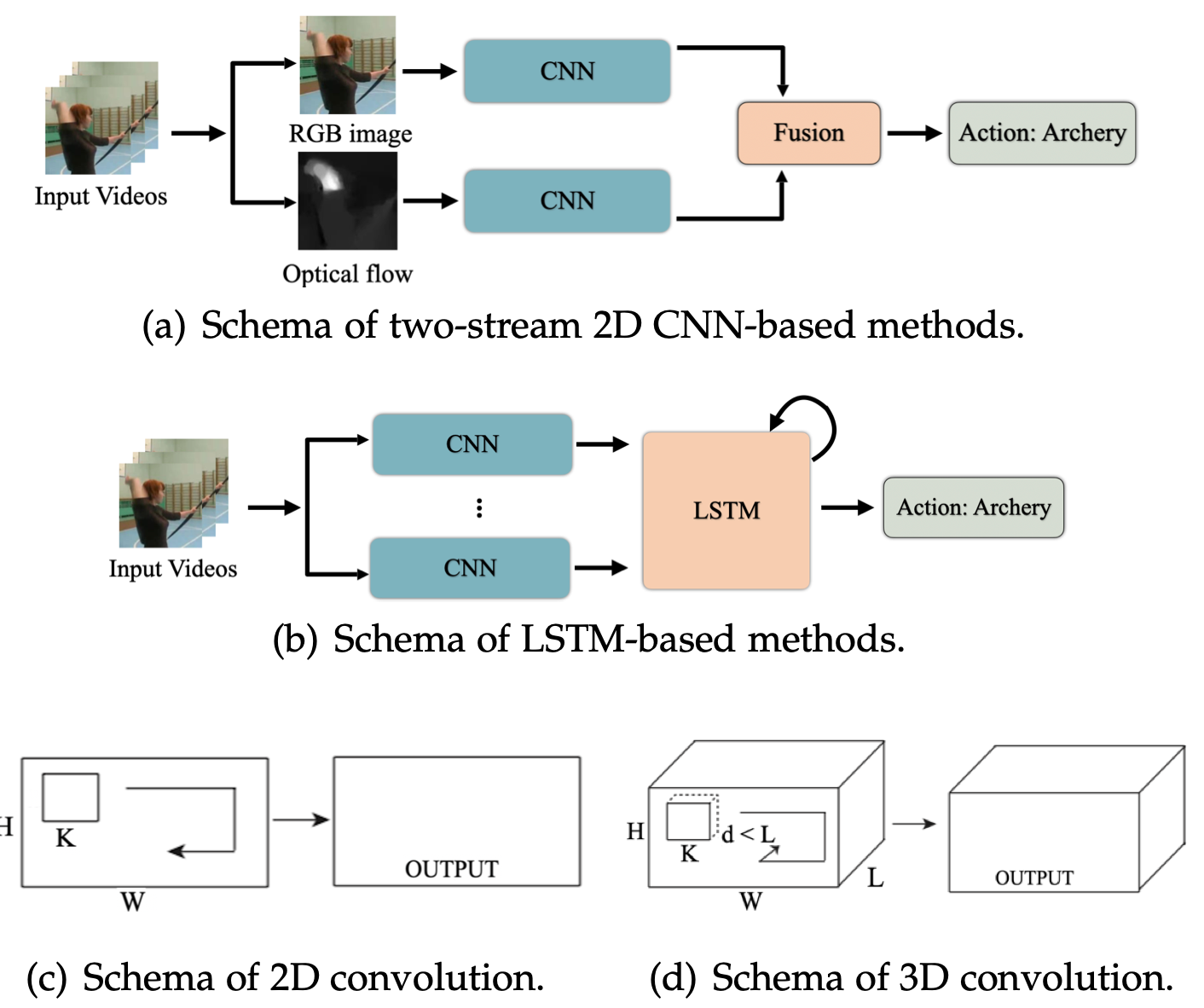 Human action recognition from various data modalities: A reviewTPAMI 2022| IEEE Transactions on Pattern Analysis and Machine IntelligenceCCF-ACORE-A*
Human action recognition from various data modalities: A reviewTPAMI 2022| IEEE Transactions on Pattern Analysis and Machine IntelligenceCCF-ACORE-A*